

A observabilidade nos aplicativos aliadas a outras ferramentas e recursos ajudam a sustentar vários indicadores de qualidade e disponibilidade, quando feita de maneira harmoniosa e correta entre todos seus elementos, sendo apoiada por três pilares : monitoramento , registro e rastreamento. O efeito positivo da observabilidade afeta diretamente a disponibilidade de ambiente e serviços, sendo este, um indicador chave e estratégico para as empresas.
A identificação da causa de um incidente precisa ser rápida e possuir processos , pessoas e sistemas adequados, funcionando de forma harmoniosa, para resolução dos problemas. Iremos discutir os conceitos da funcionalidade de HealthCheck nas aplicações .net core e como manter a relação harmoniosa com a orquestração de contêineres (Kubernetes)
O que é HealthCheck
É um middleware fornecido pelo ASP.NET CORE em conjunto com bibliotecas de verificações para relatar a integridade das dependências funcionais do aplicativo.
“Antes de adicionar verificações de integridade a um aplicativo, decida ou informe-se qual sistema de monitoramento será usado e como está configurado!. O sistema de monitoramento determina quais tipos de verificações de integridade criar e como configurar seus pontos de extremidade de verificação.” (Microsoft)
Um erro comum é achar que o fato de ter adicionado um HealthCheck em sua aplicação passou a ter um monitoramento de saúde adequado!de nada adianta relatar a integridade sem estar em harmonia com o sistema de monitoramento. O efeito negativo desta falta de harmonia podem gerar comportamentos indesejados e/ou desnecessários para a sua infraestrutura, podendo comprometer recursos e informações importantes para Troubleshooting.
O que deve ser sondando no HealthCheck
Resumidamente no HealthCheck devemos executar a sondagem de qualquer dependência necessária para o funcionamento normal e performático da aplicação (desde que cada uma destas dependências tenha condições de fornecer estas informações de forma precisa e clara).
Abaixo segue um “resumo” do que “deve ser sondado” :
- Podem ser testadas o uso de memória, disco e outros recursos físicos do servidor monitorando quanto ao seu status, quando isso impactam no funcionamento da solução e são necessariamente é um pré-requisito
- (Ex: Preciso de no mínimo X de espaço em disco, preciso de no mínimo Y de memória, preciso de um tempo de resposta máximo de Z ms.).
- Podem ser testadas as dependências de um aplicativo, como bancos de dados, cache , servidores de filas e pontos de extremidade de serviços externos, para confirmar a disponibilidade.
- Podem ser testadas as dependências de um aplicativo, como pontos de extremidade a outros serviços internos para confirmar a disponibilidade e/ou o funcionamento normal
- Ressalvas que serão discutidas no tópico ‘Castelo de Cartas’.
- Podem ser testadas variáveis de ambiente.
- Ressalva, devem ser testadas a garantia de sua existência e consistência de valores.
- Se as variáveis de ambiente não alteram seu valor (deveriam ser chamadas de constantes de ambiente….)
- Além da testagem devem ser executadas somente na inicialização (veremos como durante o artigo).
- Ressalva, devem ser testadas a garantia de sua existência e consistência de valores.
Existe uma diferença entre disponibilidade (estar acessível) de funcionamento normal(estar acessível com retornos esperados de sucesso e performance)
Este conceito será importante quando formos discutir a integração com os sistemas de monitoramento.
Qual status de saúde que deve ser retornado por cada sondagem
Para apresentar este tópico, vamos começar mostrando quais são os status de saúde que o HealthCheck retorna e o que significa cada um deles :
- Healthy : Indica que a verificação de funcionamento determinou que o componente estava íntegro e com retornos esperados de sucesso e performance.
- Degraded : Indica que a verificação de funcionamento determinou que o componente estava em estado degradado e com retornos de sucesso e/ou com sua performance comprometida. Se existir limites de timeout como indicador de saúde falhas de execução por timeout pode ser elegível para Degraded.
- Unhealthy : Indica que a verificação de funcionamento determinou que o componente não estava íntegro e com retornos esperados de falhas ou que uma exceção não tratada foi lançada durante a execução da verificação de funcionamento.
O status de saúde de um componente e/ou aplicação indicam a integridade e não o comportamento desejado em um sistema de monitoramento!
A grande dificuldade (minha opinião) que muitos desenvolvedores têm é escolher entre o Degraded e Unhealthy, principalmente quando se trata de definir o estado geral de aplicação e não do componente testado. Não existe uma definição clara e objetiva para este cenário. Por mais que se queira, sempre vai ter um “depende”. Vou apresentar como costumo fazer esta tratativa (não deve ser entendido com uma definição e/ou regra):
Em relação aos componentes individualmente
- Se existe uma métrica necessária de performance (Latência por exemplo) e não for atingindo este componente é elegível para Degraded.
- Se existe um problema de conectividade este componente é elegível para Unhealthy. (Ex: falha ao conectar no servidor de fila, banco de dados, etc.)
- Se existe um problema de conectividade em um ponto de extremidade de HealthCheck com retorno Unhealthy ou status diferente de 2XX este componente é elegível para Unhealthy com algumas ressalvas (que serão discutidas durante este artigo)
Em relação ao estado geral da Aplicação
- Se todos os componentes verificados estão com o status de Healthy o estado geral da aplicação deve ser Healthy
- Se um dos componentes verificados está com status de Degraded/ Unhealthy e não afeta a totalidade da aplicação o estado geral da aplicação é elegível para Degraded. (Ex: Componente de cache, mesmo sem cache a aplicação permanece com a capacidade de responder as solicitações com a performance comprometida).
- Se um dos componentes verificados está com status de Degraded/ Unhealthy e afeta parcialmente a aplicação (Algumas funcionalidades que não dependente deste componente funcionam) estamos em uma condição de ‘trade-off” onde deve-se decidir qual status elegível deve ser retornado Degraded/ Unhealthy (o que fazer mais sentido para a cultura da empresa e negócio da aplicação).
- Se um dos componentes verificados está com status de Unhealthy e afeta completamente o funcionamento da aplicação (todas funcionalidades depende deste componente) o estado geral da aplicação é elegível para Unhealthy.
Novamente vale lembrar que estamos discutindo o status de integridade e não o comportamento do sistema de monitoramento, e que a decisão de status pode ser subjetiva em vários cenários. O importante é existir uma definição clara e uniforme das escolhas dos status. A escolha de status de saúde se aplica somente quando o código da sondagem é feito pela aplicação ou quando utilizado bibliotecas que respeitam os parâmetros da aplicação.
Como criar um HealthCheck personalizado de forma correta
Quando registramos uma sondagem de um componente podemos definir o seu nome, o status default de falha desejado , o timeout de execução e uma lista de tags (para filtragem ; próximo tópico) desta sondagem. Um exemplo de registro:
| builder.Services.AddHealthChecks() .AddCheck(“Sample”, // Nome HealthStatus. Unhealthy, // Status de falha desejado new[] { “MeuSample” }, // Tags de filtragem TimeSpan.FromSeconds(1)); // Timeout de execução |
Uma construção personalizada de uma sondagem bem-feita deve respeitar os parâmetros de nome e status default de falha desejado passado pela aplicação. Os parâmetros definidos pela sua aplicação podem e devem ser acessados pela propriedade ‘Registration’ da classe ‘HealthCheckContext’. Segue abaixo um exemplo desta boa prática. Este exemplo assume que o status de Degraded não é considerado uma falha:
| public class SampleHealthCheck : IHealthCheck { public Task CheckHealthAsync( HealthCheckContext context, CancellationToken cancellationToken = default) { var chksta = HealthStatus.Healthy; try { // … return chksta switch { HealthStatus.Healthy => Task.FromResult( HealthCheckResult.Healthy($”{context.Registration.Name} Healthy”)), HealthStatus.Degraded => Task.FromResult( HealthCheckResult.Degraded($”{context.Registration.Name} Degraded”)), _ => Task.FromResult(new HealthCheckResult(context.Registration.FailureStatus, $”{context.Registration.Name} {context.Registration.FailureStatus}”)), }; } catch (Exception ex) { return Task.FromResult(new HealthCheckResult( context.Registration.FailureStatus, $”{context.Registration.Name} {context.Registration.FailureStatus}”,ex)); } } } |
Separação de sondagens (‘readiness’ e ‘liveness’) pela aplicação
As aplicações “modernas” (nem tanto vamos combinar…) são normalmente criadas com o paradigma de micro serviço e possuem dependências para seu domínio e eventualmente para fora do domínio (serviços externos). A integridade de saúde de sua aplicação está diretamente relacionada ao funcionamento normal destas dependências (total ou parcial).
Como já dito, existe uma diferença entre disponibilidade (estar acessível) de funcionamento normal(estar acessível com retornos esperados de sucesso e performance) e é sobre isso que este tópico vai apresentar, utilizando os conceitos abaixo:
- Liveness : Define a capacidade de sua aplicação responder a solicitações, independente do resultado das integridades.
- Readiness : Define a capacidade de sua aplicação responder de forma saudável (ou não) as solicitações.
Em outras palavras, estamos buscando o entendimento em um cenário de falha (Fonte : Microsoft):
“Readiness – Se o aplicativo está funcionando normalmente, mas não está pronto para receber solicitações. “
“Liveness – Se um aplicativo travou e deve ser reiniciado.“
Esta separação de conceito ajuda a determinar como a aplicação deseja se comportar quando informar sua integridade para o sistema de monitoramento.Segue abaixo um exemplo ”pobre” (não recomendado para produção). Este exemplo assume que o status de Healthy sempre que o Liveness é chamado.
| builder.Services.AddHealthChecks() .AddCheck(“Startup”,tags: new[] { “ready” }); // … app.MapHealthChecks(“/health/readiness”, new HealthCheckOptions { Predicate = healthCheck => healthCheck.Tags.Contains(“ready”)}); app.MapHealthChecks(“/health/liveness”, new HealthCheckOptions { Predicate = _ => false }); |
Por que este exemplo não é recomendado para produção ? Pelos itens abaixo :
- Não informa o motivo de um status de falha / degradação
- Não deixa claro o resultado da aplicação (Liveness)
A fata destas informações compromete a capacidade de identificação rápida de um problema e pode comprometer os sistemas de alertas quando observado pelo ponto de extremidade ‘Liveness’ (que sempre retorna Healthy). O componente de HealthCheck permite personalizar o resultado da operação pela propriedade HealthCheckOptions.ResponseWriter como um delegado que grava a resposta. Quanto ao resultado do ‘Liveness’, podemos enriquecer com os tipos de status disponíveis tornando mais adequado para os sistemas de alertas tomarem ações e comportamentos com base nos status. Ainda podemos tornar mais inteligente e dinâmico (aplicando uma regra de negócio) de acordo com os resultados de sondagens.
Segue abaixo um exemplo mais ”rico”. Neste exemplo é utilizado uma variável ‘static’ e ‘volatile’ para manter o resultado do ‘Liveness’ que é atualizado pelo status mais crítico do ‘Readiness’ que contenha a tag ‘required’ (regra de negócio exemplo):
| private static volatile HealthStatus AppHealthStatus = HealthStatus.Healthy; // … builder.Services.AddHealthChecks() // … app.MapHealthChecks(“/health/readiness”, new HealthCheckOptions // … private static Task CustomResponseWriter(HttpContext context, HealthReport healthReport) var reqs = healthReport.Entries context.Response.ContentType = “application/json”; return context.Response.WriteAsync(result); |
Dica : Se o objetivo é apenas atualizar o resultado do ‘Liveness’ com o status mais crítico pode-se usar a propriedade ‘Status’ da classe ‘HealthReport’
HealthCheck Passivo e Ativo
- Modo passivo : As informações de integridade dependem de um estimulo externo (chamadas aos pontos de extremidade) para serem persistidas e/ou obtidas.
- Modo ativo : A aplicação é configurada para executar sozinha as validações de integridade de tempos em tempos.
Implementando os códigos e conceitos apresentados até este momento, sua aplicação deverá ter o HealthCheck com o mínimo para funcionar e estando no modo passivo. Isso não deve ser um problema se estiver publicando em um ambiente que já tenho um sistema de monitoramento ativo (como por exemplo o Kubernetes) que fara estas chamadas periodicamente (se devidamente configurado) para monitorar a integridade de cada pod.
Do ponto de vista de sua aplicação, o modo passivo pode ser suficiente, porem podem existir cenários mais complexos onde sua aplicação possui uma lista de dependências de validações de integridade que são relativamente ‘caras’ de serem executadas (seja pelo tráfego / latência ou outro fator qualquer). Em cenários mais complexos , talvez seja mais interessante usar o modo ativo. Neste modo a execução dos HealthChecks são executados em background utilizando parâmetros globais de ‘Delay’ e ‘Period’ além do ‘Predicate’ . Os parâmetros de ‘Delay’ e ‘Period’ podem ser personalizados para cada HealthCheck. A execução em background é feita de forma independente das rotas expostas para sondagem.
Talvez em alguns cenários, seja mais interessante usar o modo ativo aliado a um cache de resultados , persistindo os resultados em memória e somente informando os resultados para as requisições que chegam. Claro que a adoção do modo ativo aliado a um cache implica em aceitar um grande ‘’trade-off’ de latência entre uma solicitação externa e a periodicidade que foi determinada para execução automática.
Esta abordagem de modo ativo aliado a um cache, pode reduzir o custo de execução das validações de integridade, melhorando a responsividade dos pontos de extremidade de validações de integridade e evitar abusos de requisições (com o custo de execução das validações de integridade) comum em ambientes complexos com muitos micros serviço que fazem chamadas para os pontos de extremidade de validações de integridade na sua aplicação (este tema será aborda em mais detalhes no tópico ‘Castelo de Cartas’ mais adiante).
Caso você opte pela abordagem de um modo ativo aliado a um cache será preciso algumas configurações adicionais em sua aplicação. Vamos a um exemplo (Apenas didático , necessariamente não representam as melhores prática e não deve ser aplicado em ambiente produtivo sem uma analise mais refinada):
| public static class CacheHealthState { private static HealthStatus _appStatus; private static HealthReport _appReport; private static DateTime _lastReport = DateTime.Now;static CacheHealthState() { _appStatus = HealthStatus.Healthy; _appReport = new HealthReport(new Dictionary<string, HealthReportEntry> { { “Live”, new HealthReportEntry(HealthStatus.Healthy, “Liveness”, TimeSpan.Zero null,null,new[] { “live” }) } }, TimeSpan.Zero); }public static HealthStatus AppStatus => _appStatus; public static HealthReport AppReport => _appReport; public static DateTime LastReport => _lastReport;internal static Task UpdateHealthState(HealthReport report, CancellationToken _) { if (report.Entries.Any()) { _lastReport = DateTime.Now; _appStatus = report.Status; _appReport = report; } return Task.CompletedTask; }public static Task ResponseReadinessFromCache(HttpContext context, HealthReport _) { context.Response.ContentType = “application/json”; var result = JsonSerializer.Serialize(new { status = _appReport.Status.ToString(), lastreport = _lastReport, dependences = _appReport.Entries.Select(e => new { key = e.Key, value = e.Value.Status.ToString() }) }); return context.Response.WriteAsync(result); }public static Task ResponseLivenessFromCache(HttpContext context, HealthReport _) { context.Response.ContentType = “text/plain”; return context.Response.WriteAsync(_appStatus.ToString()); } } |
Nota: Perceba que está sendo ignorado o parâmetro report nos métodos de ‘response’; O HealthReport vem do cache.
Criando a classe para publicar os resultados
| public class PublishHealthState : IHealthCheckPublisher { public async Task PublishAsync(HealthReport report, CancellationToken cancellationToken) { await CacheHealthState.UpdateHealthState(report,cancellationToken); } } |
Nota: Perceba que HealthReport é enviado para o método UpdateHealthState para persistir o resultado no cache.
Registrando o Publicador
| // … builder.Services.AddHealthChecks() builder.Services.Configure(options => builder.Services.AddSingleton<IHealthCheckPublisher, PublishHealthState>(); // … app.MapHealthChecks(“/health/readiness”, new HealthCheckOptions app.MapHealthChecks(“/health/liveness”, new HealthCheckOptions |
Notas: Perceba que Predicate é false. Os retornos utilizam os métodos da classe ‘CacheHealthState’.O Predicate, delay e timeout (global) para execução dos validadores são definidos na classe HealthCheckPublisherOptions.
Integrando HealthCheck com Kubernetes
Este artigo vem destacando a necessidade de uma integração harmoniosa com o sistema de monitoramento de saúde. O Kubernetes é um sistema de orquestração de contêineres open-source que automatiza a implantação, o dimensionamento e a gestão de aplicações em contêineres com inúmeras funcionalidades entre elas o monitoramento de saúde. Antes de iniciar este tópico, gostaria da sua atenção sobre o que diz a documentação (Fonte : kubernetes.io) :
“Cuidado: As sondagens de atividade podem ser uma maneira poderosa de recuperação de falhas de aplicativos, mas devem ser usadas com cautela. As sondagens de atividade devem ser configuradas cuidadosamente para garantir que realmente indiquem uma falha irrecuperável do aplicativo , por exemplo, um conflito.”
O componente de HealthCheck permite a integração com o Kubernetes pelo status http da operação do ponto de extremidade tomando como base o resultado do status de saúde. Os valores padrão são:
- Healthy : HTTP 200 (OK)
- Degraded : HTTP 200 (OK)
- Unhealthy: HTTP 503 (Service Unavailable)
Estes status podem ser customizados pela aplicação pela propriedade ‘ResultStatusCodes’ da classe ‘HealthCheckOptions’. Abaixo um exemplo :
| // … app.MapHealthChecks(“/health/readiness”, new HealthCheckOptions { // … ResultStatusCodes = new Dictionary<HealthStatus, int> { { HealthStatus.Healthy, StatusCodes.Status200OK }, { HealthStatus.Degraded, StatusCodes.Status200OK }, { HealthStatus.Unhealthy, StatusCodes.Status503ServiceUnavailable } } });app.MapHealthChecks(“/health/liveness”, new HealthCheckOptions { // … ResultStatusCodes = new Dictionary<HealthStatus, int> { { HealthStatus.Healthy, StatusCodes.Status200OK }, { HealthStatus.Degraded, StatusCodes.Status200OK }, { HealthStatus.Unhealthy, StatusCodes.Status503ServiceUnavailable } } }); |
Mas por que deveria me preocupar em customizar os status-code ? Para responder a esta pergunta primeiro vamos apresentar como o Kubernetes verifica a saúde dos pods e como se comporta quando recebe um status-code.
O ‘kubelet’ pode executar e reagir a três tipos de testes conforme a documentação (kubernetes.io)
livenessProbe
“Indica se o contêiner está em execução. Se a investigação de atividade falhar, o kubelet mata o contêiner e o contêiner fica sujeito à sua política de reinicialização . Se um contêiner não fornecer uma investigação de atividade, o estado padrão será ‘Success’.”
Quando ocorre uma falha no ‘livenessProbe’ o Kubernetes ‘mata’ o contêiner e inicia a política de reinicialização.
- Se a falha é oriunda de falta de conectividade de uma dependência o processo de reinicialização não terá nenhum efeito prático na resolução do problema uma vez que a origem do problema não está na execução ou não do contêiner.
- Se esta falha persistir por um tempo maior teremos sucessivas reinicialização do contêiner, com sobrecarga deste processo , perda da capacidade de avalição de logs e falta de visibilidade da causa raiz.
- Se a aplicação não travou ou não se encontra um estado de conflito (segundo as definições) utilizar o ‘livenessProbe’ para esta finalidade parece ser um contrassenso.
Resumindo, devolver um http status-code diferente de (2xx a 3xx) para um liveness só faz sentido quando a aplicação não é mais capaz de responder a nenhuma requisição porque está travada ou se encontra um estado de conflito.
readinessProbe
“Indica se o contêiner está pronto para responder às solicitações. Se a investigação de prontidão falhar, o controlador de endpoints removerá o endereço IP do pod dos endpoints de todos os serviços que correspondem ao pod. O estado padrão de prontidão antes do atraso inicial é ‘Failure’. Se um contêiner não fornecer uma investigação de prontidão, o estado padrão será ‘Success’.”
Quando ocorre uma falha no ‘readinessProbe’ do Kubernetes a aplicação é removida do balanceador de carga e passa a não receber mas nenhuma requisição. O contêiner continua ‘vivo’ no Kubernetes e continua a executar o ‘readinessProbe’ até que seja estabelecido o estado de saúde adequado retornando então o contêiner para o balanceador de carga.
Resumindo , devolver um http status-code diferente de (2xx a 3xx) para um readiness só faz sentido quando a aplicação é capaz de atender as requisições porém não possui uma saúde adequada para atender estas requisições de forma saudável.Sendo mais pragmático (não deve ser entendido com uma definição e/ou regra) uma tratativa mais justa seria devolver HTTP 200 para um ‘livenessProbe’ e HTTP 503 para uma falha em ‘readinessProbe’.
Descobrir e/ou definir uma ou mais regras de quando uma aplicação trava e/ou fica em estado de conflito muitas vezes pode ser bem complicado, então um HTTP 200 pode simplificar esta decisão, mas sempre tem um mas…. Quando existir a possibilidade de identificar um cenário de travamento/ conflito é desejável aplicar o status HTTP 503 no ‘livenessProbe’ quando é possível identificar um cenário de travamento/estado de conflito e executar política de reinicialização. Existem aplicações que não tem resiliência suficiente para reestabelecer a conectividade para alguns midllewares. Embora seja um débito técnico a solução nestes casos é devolver PROVISORIAMENTE HTTP 503 para o ‘liveness’ até a quitação deste débito(o mais breve possível) e deixar a aplicação executando reinicializações até a conectividade seja restabelecida devido a incapacidade da implementação de fazer a tratativa adequada a uma falha de conectividade.
StartupProbe
“Indica se o aplicativo dentro do contêiner foi iniciado. Todas as outras análises serão desabilitadas se uma análise de inicialização for fornecida, até que seja bem-sucedida. Se a investigação de inicialização falhar, o ‘kubelet’ encerra o contêiner e o contêiner fica sujeito à sua política de reinicialização . Se um contêiner não fornecer uma investigação de inicialização, o estado padrão será ‘Success’.”
Quando usar o startupProbe ?
Esta é uma boa pergunta! Existem aplicações que para estarem em estado de saúde que permita responder de forma saudável as requisições necessitam um trabalho extra e significativo durante sua inicialização, como por exemplo carregar para cache ou memória diversos dados de negócio por diversos motivos. Este trabalho extra pode afetar o resultado das operações caso as requisições comecem a chegar antes da conclusão com sucesso destas operações, principalmente se estas operações de carga são executadas em ‘background’ de forma assíncrona. Para atender este cenário pode-se utilizar o ‘startupProbe’! Criando um ponto de extremidade exclusivo na sua aplicação para atender estes critérios.
Nota final sobre este tópico
Existem vários parâmetros que devem ser configurados no Kubernetes para ajustar o intervalo de testes, ‘delay’ de atraso, número de tentativas antes de devolver um estado etc. Estes parâmetros e como configurar fogem ao escopo deste artigo. As informações sobre este tema encontram-se nas referências ao final deste artigo.
Evitando o efeito ‘Castelo de Cartas’ no Kubernetes
Aplicativos mal configurados na verificação de saúde e integridade podem causar comportamentos danosos ao ambiente como um todo.
“A implementação incorreta de testes de atividade pode levar a falhas em cascata. Isto resulta na reinicialização do contêiner sob carga elevada; solicitações de clientes com falha à medida que seu aplicativo se tornava menos escalável; e aumento da carga de trabalho nos pods restantes devido a alguns pods com falha.” (kubernetes.io)
Quando se cria uma validação de saúde para outras aplicações que também possuem sua validação de saúde podemos estar criando um verdadeiro ‘castelo de cartas’! . No mundo real podemos ter centenas ou milhares de contêiner sendo administrado pelo Kubernetes e cada contêiner pode estar solicitando uma verificação a outro conjunto de contêiner. Para um exemplo mais simples e didático vamos imaginar o cenário abaixo :
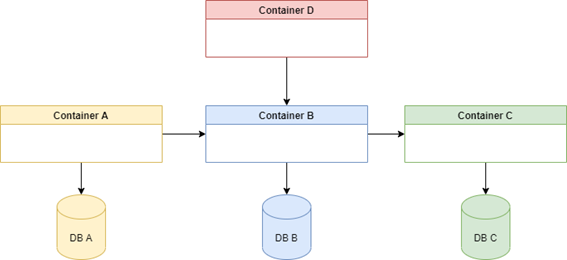
Temos neste cenário quatro aplicações , e cada uma possui suas validações integridade desejadas :
- Aplicação “A”: Se o DB-A esta integro e a Aplicação “B” esta integra.
- Aplicação “B”: Se o DB-B esta integro e a Aplicação “C” esta integra.
- Aplicação “C” : Se o DB-C esta integro.
- Aplicação “D” : Aplicação “B” esta integra (somente em relação a dependência DB-B).
Se a aplicação “C” falhar (Seja por ‘livenessProbe’ ou ‘readinessProbe’ ) o que pode acontecer ? Se “A” depende de ”B” e “B” depende de “C” podemos afirmar que “A” depende de “C”. Se todas as aplicações estiverem configuradas para reiniciar (por exemplo – livenessProbe), quando “C” começar a reiniciar fara com que “B” e “A” e ”D‘’ também reiniciem pelo efeito de propagação. Imagina isso em centenas de contêiner, o quanto se torna mais difícil identificar uma causa raiz e o quanto isso pode gerar de indisponibilidade…
Nota : Percebam pelo exemplo que teríamos uma indisponibilidade da aplicação “D” que não depende da aplicação “C” para funcionar (Somente de ‘’B” acessando DB-B).
Fica claro com este exemplo que :
Devemos ser mais criteriosos nas nossas escolhas de como implementar HealthCheck olhando para o nosso ecossistema e não apenas para necessidade de nossa aplicação. A forma que devemos tratar as dependências a outras aplicações precisam ser analisadas em separado das dependências diretas de midlleware dentro do contexto de nossa solução.
Não existe “almoço de graça” nem “bala de prata” para resolver este cenário, este aumento de complexidade é um efeito que precisa ser levado em conta quando se decide adotar uma estratégia de micro serviço por exemplo. A adoção de um barramento de mensagens em conjunto com uma abordagem orientada e eventos certamente ajudam a mitigar este efeito indesejado pois elimina ou reduz drasticamente a dependência direta de outra aplicação. Mas quando isso não é possível o que fazer ? Difícil responder a esta pergunta sem cair na armadilha de recomendar uma estratégia que não seja adequada a cada particularidade, mas vou apresentar aqui algumas abordagens ‘possíveis’ que tecnicamente tem seus “defeitos”.
Ignorar o teste de integridade para outra aplicação : Sua aplicação evita o efeito de ‘’castelo de cartas” porém perde a ‘visibilidade’ e a capacidade de informar a causa raiz de um funcionamento anormal. Certamente essa não seria minha primeira escolha…
Devolver um sempre HTTP 200 para um ‘livenessProbe’ e ‘readinessProbe’ : Sua aplicação evita o efeito de ‘’castelo de cartas” mantendo a ‘visibilidade’ e a capacidade de informar a causa raiz de um funcionamento anormal. Como não tem “almoço de graça” paga o preço de processar as requisições que certamente irão falhar, com o agravante de nem filtrar os cenários mais críticos de falhas de dependências direta dos midllewares, podendo ter sérios problemas de performance , latência e custos de execuções desnecessários e ainda podem ficar “zumbi” caso “trave” por um conflito qualquer.
Aplicar uma lógica para os testes de integridade para outra aplicação não afetarem o resultado final : Sua aplicação evita o efeito de ‘’castelo de cartas” mantendo a ‘visibilidade’ e a capacidade de informar a causa raiz de um funcionamento anormal. Como não tem “almoço de graça” paga o preço de processar as requisições que certamente irão falhar. Melhor que as anteriores mas este custo de processamento tende a ser ‘caro’ , com aumento de latência de reposta para falhas e pode gerar outros ‘’gargalos na infra”, performance , e custos de execuções desnecessários.
Aplicar uma lógica para os testes de integridade para outra aplicação não afetarem o resultado, e incluir testagem de resultado das verificações antes da execução: Esta abordagem precisa ter uma estratégia de cache de resultado e ser avaliado o intervalo de atualização deste cache. Sua aplicação evita o efeito de ‘’castelo de cartas” mantendo a ‘visibilidade’ e a capacidade de informar a causa raiz de um funcionamento anormal. Se aplicado as testagens de resultado no pipeline de execução poderá mitigar o custo de processar as requisições que certamente irão falhar. Como não tem “almoço de graça” paga o preço aumentar a complexidade pela injeção destas regras e não exime a responsabilidade de resposta ser da aplicação e não pela infraestrutura, podendo influenciar no “Upscale” de pods e custos associados. Durante o tempo do cache em falha a aplicação continuará a responder como falha mesmo que já tenha sido restabelecido a integridade, então este tempo de cache precisa ser ponderado com as condições de negócio e disponibilidade exigidos, se o tempo for muito baixo teremos uma sobre carga de testes e se for muito alta teremos uma resposta mais lenta a uma recuperação de falha.
Outras configurações
Para o Kubernetes
Os exemplos apresentando até aqui utilizam as validações de integridade por meio do protocolo HTTP . O Kubernetes fornece outros protocolos que podem ser usados quando a aplicação não possui exposição de pontos de extremidades HTTP!
O fato de sua aplicação ser um console que roda em “background service” e não ter exposição HTTP não quer dizer que ela não deve ter implementações de validação de integridade! (No final deste artigo tem um link demostrando como fazer isso, e recomendo a leitura dos outros meios de execução pelo manual do Kubernetes).
Outro ponto que merece uma atenção é pensar em adotar um “Health Checks Kubernetes Operator” para ajudar a ter uma visibilidade das causas de indisponibilidade quando a aplicação é removida do balanceador de carga e passa a não receber mas nenhuma requisição externa inclusive dos pontos de extremidade de HealthCheck. Esta adoção pode acelerar bastante a identificação da falha de integridade independente da estratégia adotada (‘livenessProbe’ ou ‘readinessProbe’)
Para o HealthCheck
Os exemplos apresentando até aqui de HealthCheck não tem nenhuma restrição quanto ao uso , são endpoints ‘abertos’ a qualquer um que tenha acesso ao recurso. Esta vulnerabilidade pode causar acessos indevidos e/ou abuso de uso. O Componente de HealthCheck possui outras funcionalidades para restringir/habilitar a sua utilização, seja por meio de identificação de ‘host / ports’, ‘authorization’ ou ‘CORS’. No final deste artigo o link de ‘Health checks in ASP.NET Core’ cobre também estes recursos e vale a leitura.
Conclusão
Espero ter deixado provocações e reflexões sobre a importância e seriedade que deve ser tratado a adoção deste recurso poderoso e muitas vezes perigoso se mal implementado, demostrado que “não basta só implementar” é preciso ter uma estratégia de adoção que seja harmônica com a sua infraestrutura.
Referências
Health checks in ASP.NET Core
https://learn.microsoft.com/en-us/aspnet/core/host-and-deploy/health-checks
Kubernetes
Monitoring Health of ASP.NET Core Background Services With TCP Probes on Kubernetes
https://dzone.com/articles/monitoring-health-of-aspnet-core-background-servic
Tenham um excelente dia! Eu sou Fernando Cerqueira e entrego estratégias digitais para os desafios do presente, com propostas de inovação para um futuro sustentável.





